





Представьте классическую картину: вы заходите на новый проект, перед вами разворачивается гигантская база данных на несколько терабайт с сотнями взаимосвязанных таблиц. Логика наименования колонок покрыта тайной, архитектор базы уволился два года назад, а бизнес требует отчет о поведении клиентов «на вчера».
Первое искушение любого новичка – написать что-то вроде SELECT * FROM orders и попытаться выгрузить всё это добро в Excel, чтобы разобраться на месте. В этот момент где-то в соседнем чате Teams начинает тихо плакать или громко ругаться администратор базы данных (DBA), ведь ваш запрос только что заблокировал работу всего продакшн-сервера компании.
В 2026 году, когда объемы корпоративной информации растут экспоненциально, умение писать чистый, быстрый и оптимизированный SQL-код – это не просто hard skill, это базовый инстинкт выживания. Давайте разберем ключевые SQL-запросы и конструкции, которые каждый аналитик данных должен знать и использовать в своей ежедневной рутине, чтобы превращать хаос цифр в чистые бизнес-инсайты.
Казалось бы, конструкция GROUP BY – это первое, чему учат на любом базовом туториале. Однако именно здесь чаще всего возникает путаница, когда нужно отфильтровать уже агрегированные данные.
Запомните золотое правило: оператор WHERE отсекает ненужные строки до того, как мозг базы данных начнет их считать и группировать. Если же вам нужно найти, например, только тех клиентов, которые совершили покупки на общую сумму более 10 000 гривен за последний месяц, WHERE вам не поможет. Здесь в игру вступает HAVING.
Пример правильной фильтрации агрегированных метрик:
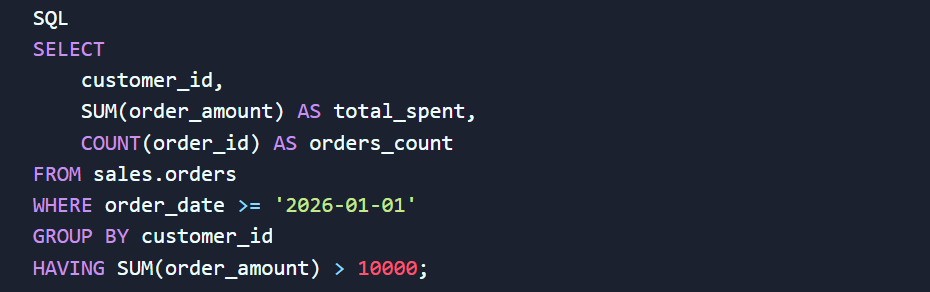
Используя эту логику, вы сначала отсекаете старые периоды с помощью WHERE (что экономит ресурсы сервера), а уже затем выбираете премиальный сегмент через HAVING.
Когда аналитическая задача становится сложной, запросы начинают обрастать подзапросами (subqueries). Через несколько часов работы ваш код превращается в кучу вложенных скобок, где один SELECT сидит внутри другого, и никто в компании, включая вас, уже не может понять, как эта конструкция работает.
Для сохранения ментального здоровья и читабельности кода существуют CTE (Common Table Expressions) – конструкция WITH. Она позволяет разбить один монструозный запрос на несколько логических, последовательных шагов, которые работают как временные виртуальные таблицы.
.png)
Любой коллега, который будет проводить код-ревью вашего отчета, искренне поблагодарит вас за такую структуру. Код читается сверху вниз, как обычная книга, а не изнутри наружу, как в случае со вложенными подзапросами.
Если на собеседовании вас спрашивают о SQL, то с вероятностью 99% разговор зайдет об оконных функциях. Это ультимативный инструмент для расчета кумулятивных итогов (running totals), скользящих средних или ранжирования элементов внутри определенных категорий без разрушения структуры самого датасета.
В отличие от GROUP BY, которая схлопывает несколько строк в одну, оконная функция OVER (PARTITION BY ...) выполняет вычисления для группы строк, но сохраняет каждую отдельную строку в финальной выгрузке.
Например, вам нужно проранжировать товары по популярности внутри каждой отдельной категории:
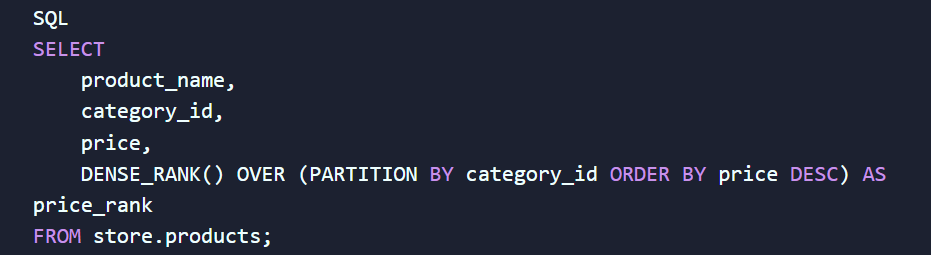
Благодаря этому запросу вы мгновенно получаете четкую иерархию продуктов в каждой категории, не используя сложные и медленные операции объединения таблиц (JOIN).
Продолжая тему оконных функций, стоит разобрать любимую задачу бизнеса – сравнение текущих показателей с предыдущими периодами (например, расчет Month-over-Month или Year-over-Year роста).
Новички для этого пытаются объединить таблицу продаж с самой собой (Self-JOIN), смещая даты. Это превращает код в тяжелого «Франкенштейна» и заставляет базу данных выполнять двойную работу. Опытный аналитик просто вызывает функции LAG() (предыдущая строка) или LEAD() (следующая строка).
%20%D1%82%D0%B0%20LAG().png)
Этот легкий запрос мгновенно выводит текущий доход, доход за прошлый месяц и чистую разницу между ними. База данных выполняет это вычисление в памяти «на лету», не нагружая дисковую подсистему сервера.
Работа со временем – это вечная боль аналитика. Сырые данные почти всегда хранятся в универсальном часовом поясе UTC. Если ваш бизнес работает в Украине, а вы просто отфильтруете данные по дате WHERE order_date = '2026-06-24', вы гарантированно потеряете заказы, которые были сделаны поздно вечером, или захватите хвост предыдущего дня.
Для точного анализа научитесь правильно приводить типы данных и работать с временными смещениями. Например, в SQL Server (T-SQL) для этого используется комбинация конструкций приведения типов и функций среза времени:
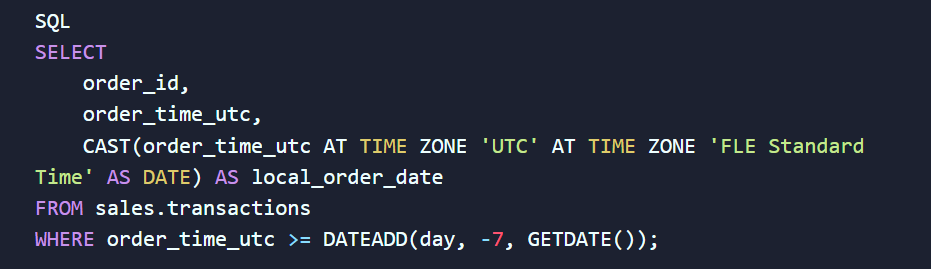
Конструкция AT TIME ZONE корректно переведет UTC-время в киевское (с учетом летнего/зимнего перехода), а CAST(... AS DATE) отбросит часы и минуты, оставляя чистый день для дальнейшей группировки. А динамический фильтр DATEADD автоматически отберет данные за последние 7 дней, избавляя вас от необходимости каждое утро переписывать даты в коде руками.
Сырые базы данных почти никогда не бывают идеальными. Они заполнены пропущенными значениями (NULL) и непонятными для бизнеса техническими статусами (например, статус заказа просто записан как число 1, 2 или 3). Задача аналитика – причесать этот хаос перед визуализацией.
Конструкция CASE WHEN работает как классический оператор IF-THEN в программировании, помогая сегментировать данные на лету:
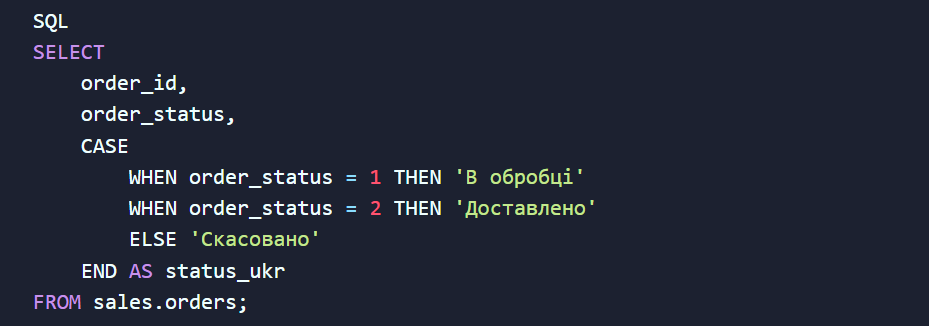
А чтобы избавиться от раздражающих пустых полей NULL, которые часто ломают расчеты и графики в BI-системах, используйте функцию COALESCE. Она возвращает первое найденное значение, не равное NULL:

Теперь, если у клиента нет телефона, система автоматически подставит емейл, а если нет и емейла – выведет понятную заглушку.
В Учебном центре «Сетевые Технологии» мы знаем, что сухая теория без реального контекста бизнеса не работает. Недостаточно просто зазубрить синтаксис команд. Нужно понимать, как работает оптимизатор запросов, как индексы влияют на скорость выборки и почему один неправильный JOIN может парализовать работу целого аналитического отдела.
Приглашаем вас на практические курсы по направлению SQL и Microsoft Data Platform в УЦ «Сетевые Технологии». На реальных кейсах разберемся, как проектировать базы данных, уверенно использовать продвинутые аналитические функции, оптимизировать сложные запросы и готовить данные для автоматической выгрузки в интерактивные дашборды Power BI.
1. В чем разница между функциями RANK(), DENSE_RANK() и ROW_NUMBER()?
Все три функции используются для нумерации или ранжирования строк в окне, но они по-разному обрабатывают одинаковые значения. ROW_NUMBER() просто последовательно нумерует строки, несмотря на одинаковые показатели. RANK() присваивает одинаковым значениям одинаковый ранг, но пропускает следующие номера (например: 1, 2, 2, 4). DENSE_RANK() также присваивает одинаковые ранги, но не делает пропусков в нумерации (например: 1, 2, 2, 3).
2. Почему оператор SELECT * считается плохой практикой в реальной работе?
Использование звездочки заставляет базу данных считывать и передавать по сети абсолютно все колонки из таблицы. Если в таблице миллионы строк и десятки полей (включая тяжелые текстовые блоки), это создает колоссальную нагрузку на диск, процессор и сетевую инфраструктуру. Кроме того, если архитекторы со временем изменят структуру таблицы (добавят или удалят колонки), ваши автоматизированные отчеты или BI-модели, завязанные на SELECT *, просто сломаются. Всегда прописывайте названия нужных колонок явно.
3. Как узнать, что мой SQL-запрос написан неэффективно и перегружает сервер?
Главный технический маркер – время выполнения запроса. Если простая выборка длится дольше нескольких секунд, стоит задуматься. Для глубокого анализа используйте команду EXPLAIN перед вашим запросом (или инструмент Execution Plan в SQL Server Management Studio). Система покажет графическую или текстовую карту того, как именно база данных выполняет ваш код. Если вы видите там «Table Scan» (полное сканирование таблицы) вместо «Index Scan» (работа по индексам) на больших массивах данных – запрос требует срочной оптимизации.
4. Нужно ли аналитику учить языки процедурного расширения SQL (например, T-SQL или PL/SQL)?
Для базового анализа и выгрузки данных достаточно стандартного синтаксиса (ANSI SQL). Однако, если вы работаете в экосистеме Microsoft Data Platform, знание T-SQL (Transact-SQL) дает огромное преимущество. Это позволит вам создавать хранимые процедуры, пользовательские функции и переменные, что критически важно для автоматизации регулярной подготовки данных и построения сложных корпоративных хранилищ данных (DWH).
5. Что такое «Non-sargable» запросы и почему они «убивают» производительность базы данных?
Термин SARGable расшифровывается как Search Argument Able. Запрос становится Non-sargable, когда вы внутри условия WHERE заворачиваете название колонки в функцию. Например, конструкция WHERE YEAR(order_date) = 2026 заставит базу данных рассчитать функцию YEAR() для каждой отдельной из миллионов строк таблицы, полностью игнорируя созданные индексы. Чтобы запрос оставался быстрым (Sargable), индексационную колонку нужно оставлять «чистой», переписав условие через диапазон: WHERE order_date >= '2026-01-01' AND order_date < '2027-01-01'.
6. В чем разница между INNER JOIN, LEFT JOIN и FULL OUTER JOIN на уровне логики выборки?
Подписывайтесь на рассылку
Будьте в курсе акций, новостей и ближайших курсов!
Copyright © 2026 Networking Technologies • Политика конфиденциальности