





Уявіть класичну картину: ви заходите на новий проєкт, перед вами розгортається гігантська база даних на кілька терабайт із сотнями взаємопов'язаних таблиць. Логіка найменування колонок покрита таємницею, архітектор бази звільнився два роки тому, а бізнес вимагає звіт про поведінку клієнтів «на вчора».
Перша спокуса будь-якого початківця – написати щось на кшталт SELECT * FROM orders і спробувати вивантажити все це добро в Excel, щоб розібратися на місці. У цей момент десь у сусідньому чаті Teams починає тихо плакати або голосно лаятися адміністратор бази даних (DBA), адже ваш запит щойно заблокував роботу всього продакшн-сервера компанії.
У 2026 році, коли обсяги корпоративної інформації зростають експоненціально, вміння писати чистий, швидкий та оптимізований SQL-код – це не просто hard skill, це базовий інстинкт виживання. Давайте розберемо ключові SQL-запити та конструкції, які кожен аналітик даних повинен знати та використовувати у своїй щоденній рутині, щоб перетворювати хаос цифр на чисті бізнес-інсайти.
Здавалося б, конструкція GROUP BY – це перше, чому вчать на будь-якому базовому туторіалі. Проте саме тут найчастіше виникає плутанина, коли потрібно відфільтрувати вже агреговані дані.
Запам'ятайте золоте правило: оператор WHERE відсікає непотрібні рядки до того, як мозок бази даних почне їх рахувати та групувати. Якщо ж вам потрібно знайти, наприклад, лише тих клієнтів, які зробили покупки на загальну суму понад 10 000 гривень за останній місяць, WHERE вам не допоможе. Тут у гру вступає HAVING.
Приклад правильної фільтрації агрегованих метрик:
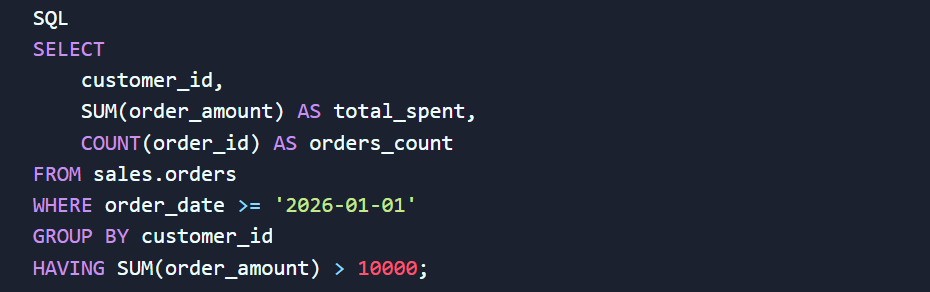
Використовуючи цю логіку, ви спочатку відсікаєте старі періоди за допомогою WHERE (що економить ресурси сервера), а вже потім вибираєте преміальний сегмент через HAVING.
Коли аналітична задача стає складною, запити починають обростати підзапитами (subqueries). Через кілька годин роботи ваш код перетворюється на купу вкладених дужок, де один SELECT сидить всередині іншого, і ніхто в компанії, включно з вами, вже не може зрозуміти, як ця конструкція працює.
Для збереження ментального здоров'я та читабельності коду існують CTE (Common Table Expressions) – конструкція WITH. Вона дозволяє розбити один монструозний запит на кілька логічних, послідовних кроків, які працюють як тимчасові віртуальні таблиці.
.png)
Будь-який колега, який проводитиме код-рев'ю вашого звіту, щиро подякує вам за таку структуру. Код читається зверху вниз, як звичайна книга, а не зсередини назовні, як у випадку із вкладеними підзапитами.
Якщо на співбесіді вас запитують про SQL, то з імовірністю 99% розмова зайде про віконні функції. Це ультимативний інструмент для розрахунку кумулятивних підсумків (running totals), ковзних середніх або ранжування елементів всередині певних категорій без руйнування структури самого датасету.
На відміну від GROUP BY, яка схлопує кілька рядків в один, віконна функція OVER (PARTITION BY ...) виконує обчислення для групи рядків, але зберігає кожен окремий рядок у фінальному вивантаженні.
Наприклад, вам потрібно проранжувати товари за популярністю всередині кожної окремої категорії:
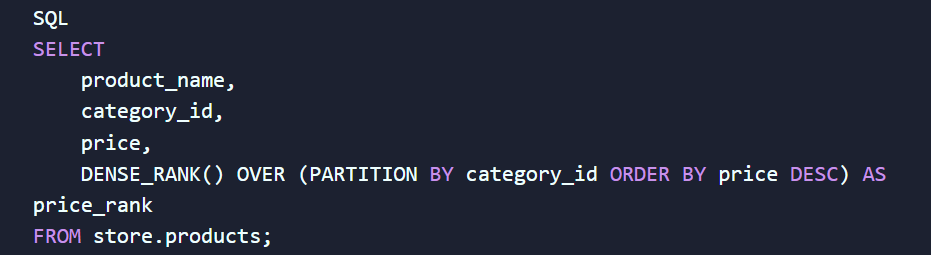
Завдяки цьому запиту ви миттєво отримуєте чітку ієрархію продуктів у кожній категорії, не використовуючи складні та повільні операції об'єднання таблиць (JOIN).
Продовжуючи тему віконних функцій, варто розібрати улюблене завдання бізнесу – порівняння поточних показників із попередніми періодами (наприклад, розрахунок Month-over-Month або Year-over-Year росту).
Новачки для цього намагаються об'єднати таблицю продажів із самою собою (Self-JOIN), зміщуючи дати. Це перетворює код на важкого «Франкенштейна» і змушує базу даних виконувати подвійну роботу. Досвідчений аналітик просто викликає функції LAG() (попередній рядок) або LEAD() (наступний рядок).
%20%D1%82%D0%B0%20LAG().png)
Цей легкий запит миттєво виводить поточний дохід, дохід за минулий місяць та чисту різницю між ними. База даних виконує це обчислення в пам'яті «на льоту», не навантажуючи дискову підсистему сервера.
Робота з часом – це вічний біль аналітика. Сирі дані майже завжди зберігаються в універсальному часовому поясі UTC. Якщо ваш бізнес працює в Україні, а ви просто відфільтруєте дані за датою WHERE order_date = '2026-06-24', ви гарантовано втратите замовлення, які були зроблені пізно ввечері, або захопите хвіст попереднього дня.
Для точного аналізу навчіться правильно приводити типи даних та працювати з часовими зміщеннями. Наприклад, у SQL Server (T-SQL) для цього використовується комбінація конструкцій приведення типів та функцій зрізання часу:
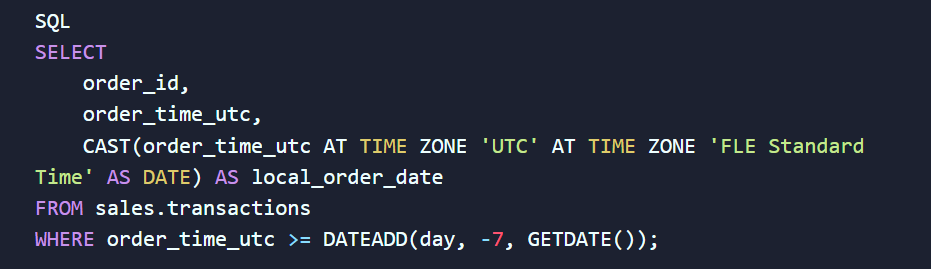
Конструкція AT TIME ZONE коректно переведе UTC-час у київський (з урахуванням літнього/зимового переходу), а CAST(... AS DATE) відкине години й хвилини, залишаючи чистий день для подальшого групування. А динамічний фільтр DATEADD автоматично відбере дані за останні 7 днів, позбавляючи вас потреби щоранку переписувати дати в коді руками.
Сирі бази даних майже ніколи не бувають ідеальними. Вони заповнені пропущеними значеннями (NULL) та незрозумілими для бізнесу технічними статусами (наприклад, статус замовлення просто записаний як число 1, 2 або 3). Завдання аналітика – причесати цей хаос перед візуалізацією.
Конструкція CASE WHEN працює як класичний оператор IF-THEN у програмуванні, допомагаючи сегментувати дані на льоту:
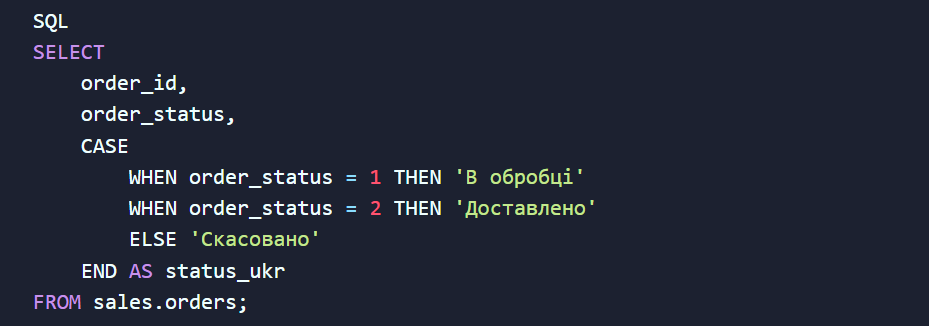
А щоб позбутися дратуючих пустих полів NULL, які часто ламають розрахунки та графіки в BI-системах, використовуйте функцію COALESCE. Вона повертає перше знайдене значення, що не дорівнює NULL:

Тепер, якщо у клієнта немає телефону, система автоматично підставить емейл, а якщо немає й емейлу – виведе зрозумілу заглушку.
У Навчальному центрі «Мережні Технології» ми знаємо, що суха теорія без реального контексту бізнесу не працює. Недостатньо просто зазубрити синтаксис команд. Потрібно розуміти, як працює оптимізатор запитів, як індекси впливають на швидкість вибірки і чому один неправильний JOIN може паралізувати роботу цілого аналітичного відділу.
Запрошуємо вас на практичні курси з напрямку SQL та Microsoft Data Platform у НЦ «Мережні Технології». На реальних кейсах розберемося, як проектувати бази даних, впевнено використовувати просунуті аналітичні функції, оптимізувати складні запити та готувати дані для автоматичного вивантаження в інтерактивні дашборди Power BI.
1. У чому різниця між функціями RANK(), DENSE_RANK() та ROW_NUMBER()?
Усі три функції використовуються для нумерації або ранжування рядків у вікні, але вони по-різному обробляють однакові значення. ROW_NUMBER() просто послідовно нумерує рядки, попри однакові показники. RANK() присвоює однаковим значенням однаковий ранг, але пропускає наступні номери (наприклад: 1, 2, 2, 4). DENSE_RANK() також присвоює однакові ранги, але не робить пропусків у нумерації (наприклад: 1, 2, 2, 3).
2. Чому оператор SELECT * вважається поганою практикою в реальній роботі?
Використання зірочки змушує базу даних зчитувати та передавати по мережі абсолютно всі колонки з таблиці. Якщо в таблиці мільйони рядків та десятки полів (включаючи важкі текстові блоги), це створює колосальне навантаження на диск, процесор та мережеву інфраструктуру. Окрім того, якщо архітектори згодом змінять структуру таблиці (додадуть або видалять колонки), ваші автоматизовані звіти чи BI-моделі, зав'язані на SELECT *, просто зламаються. Завжди прописуйте назви потрібних колонок явно.
3. Як дізнатися, що мій SQL-запит написаний неефективно і перевантажує сервер?
Головний технічний маркер – час виконання запиту. Якщо проста вибірка триває довше кількох секунд, варто задуматися. Для глибокого аналізу використовуйте команду EXPLAIN перед вашим запитом (або інструмент Execution Plan у SQL Server Management Studio). Система покаже графічну або текстову карту того, як саме база даних виконує ваш код. Якщо ви бачити там «Table Scan» (повне сканування таблиці) замість «Index Scan» (робота за індексами) на великих масивах даних – запит потребує термінової оптимізації.
4. Чи потрібно аналітику вчити мови процедурного розширення SQL (наприклад, T-SQL або PL/SQL)?
Для базового аналізу та вивантаження даних достатньо стандартного синтаксису (ANSI SQL). Проте, якщо ви працюєте в екосистемі Microsoft Data Platform, знання T-SQL (Transact-SQL) дає величезну перевагу. Це дозволить вам створювати збережені процедури, користувацькі функції та змінні, що критично важливо для автоматизації регулярної підготовки даних та побудови складних корпоративних сховищ даних (DWH).
5. Що таке «Non-sargable» запити і чому вони «вбивають» продуктивність бази даних?
Термін SARGable розшифровується як Search Argument Able. Запит стає Non-sargable, коли ви всередині умови WHERE загортаєте назву колонки у функцію. Наприклад, конструкція WHERE YEAR(order_date) = 2026 змусить базу даних розрахувати функцію YEAR() для кожного окремого з мільйонів рядків таблиці, повністю ігноруючи створені індекси. Щоб запит залишався швидким (Sargable), індексаційну колонку потрібно залишати «чистою», переписавши умову через діапазон: WHERE order_date >= '2026-01-01' AND order_date < '2027-01-01'.
6. У чому різниця між INNER JOIN, LEFT JOIN та FULL OUTER JOIN на рівні логіки вибірки?
Підписуйтесь на розсилку
Будьте в курсі акцій, новин і найближчих курсів!
Copyright © 2026 Networking Technologies • Політика конфіденційності